Redux Essentials, パート 8: RTK Query の高度なパターン
- キャッシュの無効化と再フェッチを管理するために ID 付きのタグを使用する方法
- React の外部で RTK Query キャッシュを操作する方法
- レスポンスデータを操作するテクニック
- 楽観的更新とストリーミング更新の実装
- パート 7 を完了し、RTK Query のセットアップと基本的な使用方法を理解していること
導入
パート 7: RTK Query の基礎では、RTK Query API を設定して、アプリケーションでのデータフェッチとキャッシュを処理する方法を学びました。Redux ストアに「API スライス」を追加し、投稿データをフェッチするための「クエリ」エンドポイントと、新しい投稿を追加するための「ミューテーション」エンドポイントを定義しました。
このセクションでは、他のデータ型で RTK Query を使用するようにサンプルアプリを移行し続け、その高度な機能を使用してコードベースを簡素化し、ユーザーエクスペリエンスを向上させる方法を見ていきます。
このセクションの一部の変更は厳密には必要ありません。RTK Query の機能を示すため、および必要に応じてこれらの機能を使用する方法を確認できるように、実行できることの一部を示すために含まれています。
投稿の編集
新しい投稿エントリをサーバーに保存するためのミューテーションエンドポイントを既に追加し、それを <AddPostForm> で使用しました。次に、既存の投稿を編集できるように、<EditPostForm> の更新を処理する必要があります。
投稿編集フォームの更新
投稿の追加と同様に、最初のステップは、API スライスに新しいミューテーションエンドポイントを定義することです。これは投稿を追加するためのミューテーションとよく似ていますが、エンドポイントは URL に投稿 ID を含め、HTTP PATCH リクエストを使用してフィールドの一部を更新していることを示す必要があります。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation({
query: post => ({
url: `/posts/${post.id}`,
method: 'PATCH',
body: post
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
追加が完了したら、<EditPostForm> を更新できます。元の Post エントリをストアから読み取り、それを使用してコンポーネントの状態を初期化してフィールドを編集し、更新された変更をサーバーに送信する必要があります。現在、selectPostById を使用して Post エントリを読み取り、リクエストのために postUpdated thunk を手動でディスパッチしています。
<SinglePostPage> で使用したのと同じ useGetPostQuery フックを使用して、ストアのキャッシュから Post エントリを読み取ることができ、新しい useEditPostMutation フックを使用して変更の保存を処理します。
import React, { useState } from 'react'
import { useHistory } from 'react-router-dom'
import { Spinner } from '../../components/Spinner'
import { useGetPostQuery, useEditPostMutation } from '../api/apiSlice'
export const EditPostForm = ({ match }) => {
const { postId } = match.params
const { data: post } = useGetPostQuery(postId)
const [updatePost, { isLoading }] = useEditPostMutation()
const [title, setTitle] = useState(post.title)
const [content, setContent] = useState(post.content)
const history = useHistory()
const onTitleChanged = e => setTitle(e.target.value)
const onContentChanged = e => setContent(e.target.value)
const onSavePostClicked = async () => {
if (title && content) {
await updatePost({ id: postId, title, content })
history.push(`/posts/${postId}`)
}
}
// omit rendering logic
}
キャッシュデータのサブスクリプションのライフタイム
これを試して、何が起こるか見てみましょう。ブラウザの DevTools を開き、[ネットワーク] タブに移動して、メインページを更新します。初期データをフェッチするときに、/posts への GET リクエストが表示されるはずです。[投稿を表示] ボタンをクリックすると、その単一の投稿エントリを返す /posts/:postId への 2 番目のリクエストが表示されるはずです。
次に、単一の投稿ページ内で [投稿の編集] をクリックします。UI が切り替わって <EditPostForm> が表示されますが、今回は個々の投稿に対するネットワークリクエストはありません。なぜですか?

RTK Query では、複数のコンポーネントが同じデータをサブスクライブでき、一意のデータセットが 1 回だけフェッチされることを保証します。 内部的には、RTK Query は、各エンドポイント + キャッシュキーの組み合わせへのアクティブな「サブスクリプション」の参照カウンターを保持します。コンポーネント A が useGetPostQuery(42) を呼び出すと、そのデータがフェッチされます。コンポーネント B がマウントされ、useGetPostQuery(42) も呼び出すと、まったく同じデータが要求されます。2 つのフックの使用法は、フェッチされた data やロードステータスフラグを含むまったく同じ結果を返します。
アクティブなサブスクリプションの数が 0 になると、RTK Query は内部タイマーを開始します。データの新しいサブスクリプションが追加される前にタイマーの有効期限が切れると、アプリがデータを必要としなくなるため、RTK Query はキャッシュからそのデータを自動的に削除します。 ただし、タイマーの有効期限が切れる前に新しいサブスクリプションが追加された場合、タイマーはキャンセルされ、すでにキャッシュされたデータが再フェッチされることなく使用されます。
この場合、<SinglePostPage> がマウントされ、ID でその個々の Post をリクエストしました。[投稿の編集] をクリックしたとき、<SinglePostPage> コンポーネントはルーターによってアンマウントされ、アンマウントによりアクティブなサブスクリプションが削除されました。RTK Query は直ちに「この投稿データを削除する」タイマーを開始しました。ただし、<EditPostPage> コンポーネントがすぐにマウントされ、同じキャッシュキーで同じ Post データをサブスクライブしました。したがって、RTK Query はタイマーをキャンセルし、サーバーからフェッチするのではなく、同じキャッシュされたデータを使用し続けました。
デフォルトでは、未使用のデータは 60 秒後にキャッシュから削除されますが、これはルート API スライスの定義で構成するか、秒単位のキャッシュの有効期間を指定する keepUnusedDataFor フラグを使用して個々のエンドポイント定義でオーバーライドできます。
特定の項目の無効化
<EditPostForm> コンポーネントは編集された投稿をサーバーに保存できるようになりましたが、問題があります。編集中に [投稿を保存] をクリックすると、<SinglePostPage> に戻りますが、編集されていない古いデータが表示されたままです。<SinglePostPage> は、以前にフェッチされたキャッシュされた Post エントリをまだ使用しています。そのため、メインページに戻って <PostsList> を見ると、古いデータも表示されます。個々の Post エントリと投稿リスト全体の両方の再フェッチを強制する方法が必要です。
以前に、キャッシュされたデータの一部を無効にするために「タグ」を使用する方法を見ました。getPosts クエリエンドポイントが 'Post' タグを提供し、addNewPost ミューテーションエンドポイントが同じ 'Post' タグを無効化することを宣言しました。これにより、新しい投稿を追加するたびに、RTK Query は getQuery エンドポイントから投稿リスト全体を強制的に再フェッチします。
'Post' タグを getPost クエリと editPost ミューテーションの両方に追加できますが、それによって他のすべての個々の投稿も強制的に再フェッチされます。幸いなことに、RTK Query では、特定のタグを定義して、データの無効化をより選択的に行うことができます。これらの特定のタグは、{type: 'Post', id: 123} のようになります。
getPosts クエリは、文字列の配列である providesTags フィールドを定義します。providesTags フィールドは、result および arg を受け取り、配列を返すコールバック関数も受け入れることができます。これにより、フェッチされているデータの ID に基づいてタグエントリを作成できます。同様に、invalidatesTags もコールバックにできます。
正しい動作を得るには、各エンドポイントを適切なタグで設定する必要があります
getPosts:リスト全体に対する一般的な'Post'タグと、受信した各投稿オブジェクトに対する特定の{type: 'Post', id}タグを提供しますgetPost:個々の投稿オブジェクトに対する特定の{type: 'Post', id}オブジェクトを提供しますaddNewPost:リスト全体を再フェッチするために、一般的な'Post'タグを無効化しますeditPost:特定の{type: 'Post', id}タグを無効化します。これにより、getPostからの 個々の 投稿と、getPostsからの投稿リスト 全体 の両方が強制的に再フェッチされます。これらはどちらも、その{type, id}値に一致するタグを提供するためです。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts',
providesTags: (result = [], error, arg) => [
'Post',
...result.map(({ id }) => ({ type: 'Post', id }))
]
}),
getPost: builder.query({
query: postId => `/posts/${postId}`,
providesTags: (result, error, arg) => [{ type: 'Post', id: arg }]
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
}),
invalidatesTags: (result, error, arg) => [{ type: 'Post', id: arg.id }]
})
})
})
これらのコールバックのresult引数は、レスポンスにデータがない場合やエラーが発生した場合にundefinedになる可能性があるため、安全に処理する必要があります。getPostsについては、マッピングするデフォルトの引数配列値を使用することで対応でき、getPostについては、引数IDに基づいて単一項目の配列をすでに返しています。editPostについては、トリガー関数に渡された部分的な投稿オブジェクトから投稿のIDがわかっているので、そこから読み取ることができます。
これらの変更を適用した状態で、もう一度投稿の編集を試してみましょう。ブラウザの開発者ツールのNetworkタブを開いた状態で行います。
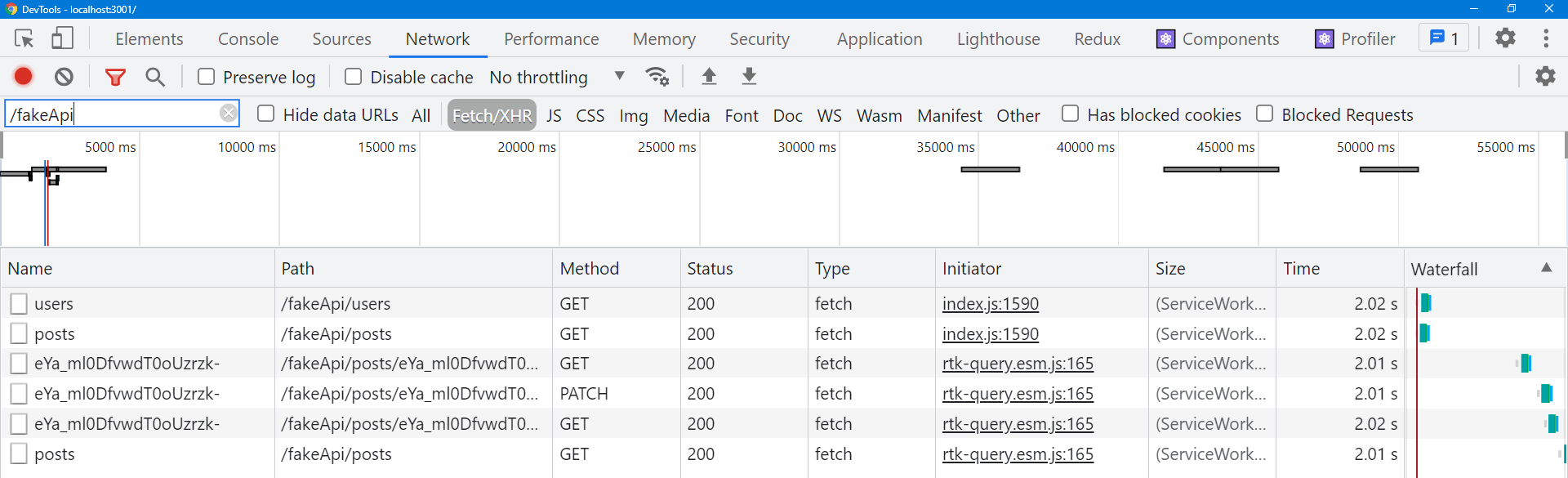
今回は編集した投稿を保存すると、2つのリクエストが連続して発生するはずです。
editPostミューテーションからのPATCH /posts/:postIdgetPostクエリが再フェッチされるため発生するGET /posts/:postId
そして、メインの「投稿」タブに戻ると、以下のリクエストも表示されるはずです。
getPostsクエリが再フェッチされるため発生するGET /posts
タグを使用してエンドポイント間の関係を提供したため、RTK Queryは、編集を行ったときに個々の投稿と投稿リストを再フェッチする必要があること、およびそのIDを持つ特定のタグが無効化されたことを認識しました。これ以上の変更は必要ありませんでした。一方、投稿を編集している間に、getPostsデータのキャッシュ削除タイマーが期限切れになったため、キャッシュから削除されました。<PostsList>コンポーネントを再度開いたとき、RTK Queryはキャッシュにデータがないことを認識し、再フェッチしました。
ただし、1つ注意点があります。getPostsで単純な'Post'タグを指定し、addNewPostでそれを無効化すると、実際にはすべての個々の投稿も再フェッチすることになります。getPostエンドポイントの投稿リストのみを再フェッチしたい場合は、{type: 'Post', id: 'LIST'}のような任意のIDを持つ追加のタグを含め、代わりにそのタグを無効化することができます。RTK Queryのドキュメントには、特定の一般的/特定のタグの組み合わせが無効化された場合に何が起こるかを説明する表があります。
RTK Queryには、データのリフェッチをいつ、どのように制御するかについて、他に多くのオプションがあります。「条件付きフェッチ」、「レイジー クエリ」、「プリフェッチ」などがあり、クエリの定義はさまざまな方法でカスタマイズできます。これらの機能の使用に関する詳細については、RTK Queryの使用ガイドのドキュメントを参照してください。
ユーザーデータの管理
投稿データの管理をRTK Queryを使用するように変換することが完了しました。次は、ユーザーリストを変換します。
データのフェッチと読み取りにRTK Queryフックを使用する方法はすでに確認済みなので、このセクションでは別の方法を試します。RTK QueryのコアAPIはUIに依存せず、Reactだけでなく、任意のUIレイヤーで使用できます。通常はフックを使用することをお勧めしますが、ここではRTK QueryコアAPIのみを使用してユーザーデータを使用し、その方法を確認します。
手動でのユーザーのフェッチ
現在、usersSlice.jsでfetchUsers非同期サンクを定義し、index.jsでそのサンクを手動でディスパッチして、ユーザーリストをできるだけ早く利用できるようにしています。RTK Queryを使用して同じプロセスを実行できます。
まず、既存のエンドポイントと同様に、apiSlice.jsにgetUsersクエリのエンドポイントを定義します。一貫性を保つためにuseGetUsersQueryフックをエクスポートしますが、今のところは使用しません。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
getUsers: builder.query({
query: () => '/users'
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useGetUsersQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
APIスライスオブジェクトを調べると、定義したエンドポイントごとに1つのエンドポイントオブジェクトを含むendpointsフィールドが含まれています。

各エンドポイントオブジェクトには以下が含まれています。
- ルートAPIスライスオブジェクトからエクスポートしたのと同じプライマリクエリ/ミューテーションフックですが、
useQueryまたはuseMutationとして名前が付けられています。 - クエリエンドポイントの場合、「レイジー クエリ」や部分的なサブスクリプションのようなシナリオのための追加のクエリフックのセット
- このエンドポイントに対するリクエストによってディスパッチされる
pending/fulfilled/rejectedアクションを確認するための「マッチャー」ユーティリティのセット - このエンドポイントのリクエストをトリガーする
initiateサンク - このエンドポイントのキャッシュされた結果データ+ステータスエントリを取得できるメモ化されたセレクターを作成する
select関数
Reactの外部でユーザーリストをフェッチしたい場合は、インデックスファイルでgetUsers.initiate()サンクをディスパッチできます。
// omit other imports
import { apiSlice } from './features/api/apiSlice'
async function main() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSlice.endpoints.getUsers.initiate())
ReactDOM.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>,
document.getElementById('root')
)
}
main()
このディスパッチはクエリフック内部で自動的に行われますが、必要に応じて手動で開始できます。
RTKQリクエストサンクを手動でディスパッチすると、サブスクリプションエントリが作成されますが、その後、後でそのデータからサブスクライブを解除する必要があります。そうしないと、データはキャッシュに永久に残ります。この場合、常にユーザーデータが必要なため、サブスクライブを解除する必要はありません。
ユーザーデータの選択
現在、selectAllUsersやselectUserByIdのようなセレクターがあり、createEntityAdapterユーザーアダプターによって生成され、state.usersから読み取られています。ページをリロードすると、state.usersスライスにデータがないため、ユーザー関連の表示がすべて壊れてしまいます。RTK Queryのキャッシュのデータをフェッチするようになったため、これらのセレクターをキャッシュから読み取る同等のセレクターに置き換える必要があります。
APIスライスエンドポイントのendpoint.select()関数は、呼び出すたびに新しいメモ化されたセレクター関数を作成します。select()は引数としてキャッシュキーを取り、これはクエリフックまたはinitiate()サンクのいずれかに引数として渡す同じキャッシュキーである必要があります。生成されたセレクターは、そのキャッシュキーを使用して、ストアのキャッシュ状態からどのキャッシュされた結果を返す必要があるかを正確に把握します。
この場合、getUsersエンドポイントはパラメーターを必要としません。常にユーザーリスト全体をフェッチします。したがって、引数のないキャッシュセレクターを作成でき、キャッシュキーはundefinedになります。
import {
createSlice,
createEntityAdapter,
createSelector
} from '@reduxjs/toolkit'
import { apiSlice } from '../api/apiSlice'
/* Temporarily ignore adapter - we'll use this again shortly
const usersAdapter = createEntityAdapter()
const initialState = usersAdapter.getInitialState()
*/
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSlice.endpoints.getUsers.select()
const emptyUsers = []
export const selectAllUsers = createSelector(
selectUsersResult,
usersResult => usersResult?.data ?? emptyUsers
)
export const selectUserById = createSelector(
selectAllUsers,
(state, userId) => userId,
(users, userId) => users.find(user => user.id === userId)
)
/* Temporarily ignore selectors - we'll come back to this later
export const {
selectAll: selectAllUsers,
selectById: selectUserById,
} = usersAdapter.getSelectors((state) => state.users)
*/
初期のselectUsersResultセレクターを作成したら、既存のselectAllUsersセレクターをキャッシュ結果からユーザーの配列を返すセレクターに置き換え、selectUserByIdをその配列から適切なユーザーを見つけるセレクターに置き換えることができます。
今のところ、usersAdapterのセレクターはコメントアウトします。後で、それらを再度使用するように切り替える別の変更を行います。
コンポーネントはすでにselectAllUsersとselectUserByIdをインポートしているため、この変更はそのまま機能するはずです。ページを更新して、投稿リストと単一の投稿ビューをクリックしてみてください。正しいユーザー名が各表示された投稿と、<AddPostForm>のドロップダウンに表示されるはずです。
usersSliceはもはやまったく使用されていないため、このファイルからcreateSlice呼び出しを削除し、ストアのセットアップからusers: usersReducerを削除できます。postsSliceを参照するコードがまだいくつかあるため、まだ完全に削除することはできません。それについては後ほど説明します。
エンドポイントの注入
大規模なアプリケーションでは、機能を個別のバンドルに「コード分割」し、機能が初めて使用されるときにオンデマンドで「遅延ロード」するのが一般的です。RTK Queryには通常、アプリケーションごとに単一の「APIスライス」があり、これまでのところ、すべてのエンドポイントをapiSlice.jsで直接定義しました。エンドポイント定義の一部をコード分割したり、APIスライスファイルが大きくなりすぎないように別のファイルに移動したい場合はどうなるでしょうか?
RTK Queryは、apiSlice.injectEndpoints()を使用してエンドポイント定義を分割することをサポートしています。そうすることで、単一のミドルウェアとキャッシュリデューサーを持つ単一のAPIスライスを維持したまま、一部のエンドポイントの定義を別のファイルに移動できます。これにより、コード分割のシナリオが可能になるだけでなく、必要に応じて機能フォルダーと一緒に一部のエンドポイントを配置することもできます。
このプロセスを説明するために、getUsersエンドポイントをapiSlice.jsで定義するのではなく、usersSlice.jsに注入するように切り替えましょう。
getUsersエンドポイントにアクセスできるように、apiSliceをすでにusersSlice.jsにインポートしているので、ここでapiSlice.injectEndpoints()を呼び出すように切り替えることができます。
import { apiSlice } from '../api/apiSlice'
export const extendedApiSlice = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query({
query: () => '/users'
})
})
})
export const { useGetUsersQuery } = extendedApiSlice
export const selectUsersResult = extendedApiSlice.endpoints.getUsers.select()
injectEndpoints()は、追加のエンドポイント定義を追加するために元のAPIスライスオブジェクトを変更し、それを返します。ストアに最初に追加した実際のキャッシュリデューサーとミドルウェアは、引き続き正常に機能します。現時点では、apiSliceとextendedApiSliceは同じオブジェクトですが、ここでのapiSliceの代わりにextendedApiSliceオブジェクトを参照すると、自分自身へのリマインダーとして役立ちます。(これはTypeScriptを使用している場合により重要です。なぜなら、extendedApiSlice値のみが新しいエンドポイントの追加された型を持っているからです。)
現時点では、getUsersエンドポイントを参照する唯一のファイルは、initiateサンクをディスパッチしているインデックスファイルです。代わりに拡張APIスライスをインポートするように更新する必要があります。
// omit other imports
- import { apiSlice } from './features/api/apiSlice'
+ import { extendedApiSlice } from './features/users/usersSlice'
async function main() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
- store.dispatch(apiSlice.endpoints.getUsers.initiate())
+ store.dispatch(extendedApiSlice.endpoints.getUsers.initiate())
ReactDOM.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>,
document.getElementById('root')
)
}
main()
または、スライスファイルから特定のエンドポイント自体をエクスポートすることもできます。
レスポンスデータの操作
これまでのところ、すべてのクエリエンドポイントは、サーバーからのレスポンスデータを本文で受信したとおりに正確に保存していました。getPostsとgetUsersはどちらもサーバーが配列を返すことを期待し、getPostは個々のPostオブジェクトを本文として期待しています。
クライアントがサーバーレスポンスからデータの断片を抽出したり、キャッシュする前にデータを何らかの方法で変換したりする必要があるのが一般的です。たとえば、/getPostリクエストが{post: {id}}のような本文を返し、データがネストしている場合はどうなるでしょうか?
この概念を処理する方法はいくつかあります。1つの選択肢は、レスポンス全体のボディではなく、responseData.postフィールドを抽出してキャッシュに保存することです。もう1つは、レスポンスデータ全体をキャッシュに保存し、コンポーネントが必要とするキャッシュデータの特定の部分のみを指定することです。
レスポンスの変換
エンドポイントは、キャッシュされる前にサーバーから受信したデータを抽出または変更できるtransformResponseハンドラーを定義できます。getPostの例では、transformResponse: (responseData) => responseData.postとすると、レスポンスのボディ全体ではなく、実際のPostオブジェクトのみがキャッシュされます。
パート6:パフォーマンスと正規化では、データを正規化された構造で保存することが役立つ理由について説明しました。特に、正しいアイテムを見つけるために配列をループ処理する必要がなく、IDに基づいてアイテムを検索および更新できるようになります。
現在、selectUserByIdセレクターは、正しいUserオブジェクトを見つけるために、キャッシュされたユーザーの配列をループ処理する必要があります。レスポンスデータを正規化されたアプローチを使用して保存するように変換すると、それをIDで直接ユーザーを検索するように簡略化できます。
以前は、正規化されたユーザーデータを管理するために、usersSliceでcreateEntityAdapterを使用していました。createEntityAdapterをextendedApiSliceに統合し、実際にcreateEntityAdapterを使用して、キャッシュされる前にデータを変換できます。元々あったusersAdapterの行のコメントを解除し、その更新関数とセレクターを再び使用します。
import { apiSlice } from '../api/apiSlice'
const usersAdapter = createEntityAdapter()
const initialState = usersAdapter.getInitialState()
export const extendedApiSlice = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query({
query: () => '/users',
transformResponse: responseData => {
return usersAdapter.setAll(initialState, responseData)
}
})
})
})
export const { useGetUsersQuery } = extendedApiSlice
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = extendedApiSlice.endpoints.getUsers.select()
const selectUsersData = createSelector(
selectUsersResult,
usersResult => usersResult.data
)
export const { selectAll: selectAllUsers, selectById: selectUserById } =
usersAdapter.getSelectors(state => selectUsersData(state) ?? initialState)
getUsersエンドポイントにtransformResponseオプションを追加しました。これは、レスポンスデータボディ全体を引数として受け取り、キャッシュされる実際のデータを返す必要があります。usersAdapter.setAll(initialState, responseData)を呼び出すことで、受信したすべてのアイテムを含む標準の{ids: [], entities: {}}正規化されたデータ構造が返されます。
adapter.getSelectors()関数は、その正規化されたデータがどこにあるかを認識するために、「入力セレクター」を与える必要があります。この場合、データはRTK Queryキャッシュリデューサー内にネストされているため、キャッシュ状態から正しいフィールドを選択します。
正規化キャッシュとドキュメントキャッシュ
少し立ち止まって、先ほど行ったことをさらに詳しく説明する価値があります。
Apolloのような他のデータフェッチライブラリに関連して、「正規化されたキャッシュ」という用語を聞いたことがあるかもしれません。RTK Queryは「正規化されたキャッシュ」ではなく、「ドキュメントキャッシュ」のアプローチを使用していることを理解することが重要です。
完全に正規化されたキャッシュは、アイテムタイプとIDに基づいて、すべてのクエリで同様のアイテムを重複排除しようとします。例として、getTodosエンドポイントとgetTodoエンドポイントを持つAPIスライスがあり、コンポーネントが次のクエリを作成するとします。
getTodos()getTodos({filter: 'odd'})getTodo({id: 1})
これらの各クエリの結果には、{id: 1}のようなTodoオブジェクトが含まれます。
完全に正規化された重複排除キャッシュでは、このTodoオブジェクトのコピーは1つだけ保存されます。ただし、RTK Queryは各クエリ結果をキャッシュに個別に保存します。したがって、これは、このTodoの3つの別々のコピーがReduxストアにキャッシュされることになります。ただし、すべてのエンドポイントが常に同じタグ({type: 'Todo', id: 1}など)を提供している場合、そのタグを無効にすると、一致するすべてのエンドポイントが整合性を保つためにデータを再フェッチする必要があります。
RTK Queryは、複数のリクエスト間で同一のアイテムを重複排除するキャッシュを意図的に実装していません。これにはいくつかの理由があります。
- 完全に正規化されたクエリ間で共有されるキャッシュは、解決するのが難しい問題です。
- 今すぐそれを解決しようとする時間、リソース、または関心がありません。
- 多くの場合、無効化されたときにデータを再フェッチするだけでうまく機能し、理解しやすくなります。
- 少なくとも、RTKQは「いくつかのデータをフェッチする」という一般的なユースケースを解決するのに役立ちます。これは多くの人にとって大きな問題点です。
比較すると、getUsersエンドポイントのレスポンスデータを正規化しました。これは、{[id]: value}のルックアップテーブルとして保存されています。ただし、これは「正規化されたキャッシュ」と同じものではありません。エンドポイントまたはリクエスト間で結果を重複排除するのではなく、この1つのレスポンスが保存される方法を変換しただけです。
結果からの値の選択
古いpostsSliceから読み取っている最後のコンポーネントは<UserPage>で、現在のユーザーに基づいて投稿のリストをフィルタリングします。useGetPostsQuery()で投稿のリスト全体を取得し、コンポーネント内で変換できることはすでに見てきました。たとえば、useMemo内でソートするなどです。クエリフックでは、selectFromResultオプションを提供することで、キャッシュされた状態の一部を選択し、選択された部分が変更された場合にのみ再レンダリングすることもできます。
selectFromResultを使用して、<UserPage>がキャッシュからフィルタリングされた投稿のリストのみを読み取るようにできます。ただし、selectFromResultが不要な再レンダリングを回避するためには、抽出するデータが正しくメモ化されていることを確認する必要があります。これを行うには、<UsersPage>コンポーネントがレンダリングするたびに再利用できる新しいセレクターインスタンスを作成する必要があります。これにより、セレクターは入力に基づいて結果をメモ化します。
import { createSelector } from '@reduxjs/toolkit'
import { selectUserById } from '../users/usersSlice'
import { useGetPostsQuery } from '../api/apiSlice'
export const UserPage = ({ match }) => {
const { userId } = match.params
const user = useSelector(state => selectUserById(state, userId))
const selectPostsForUser = useMemo(() => {
const emptyArray = []
// Return a unique selector instance for this page so that
// the filtered results are correctly memoized
return createSelector(
res => res.data,
(res, userId) => userId,
(data, userId) => data?.filter(post => post.user === userId) ?? emptyArray
)
}, [])
// Use the same posts query, but extract only part of its data
const { postsForUser } = useGetPostsQuery(undefined, {
selectFromResult: result => ({
// We can optionally include the other metadata fields from the result here
...result,
// Include a field called `postsForUser` in the hook result object,
// which will be a filtered list of posts
postsForUser: selectPostsForUser(result, userId)
})
})
// omit rendering logic
}
ここで作成したメモ化されたセレクター関数には、重要な違いがあります。通常、セレクターは、最初の引数としてReduxのstate全体を予期し、stateから値を取り出すか派生させます。ただし、この場合、キャッシュに保持されている「結果」値のみを扱っています。結果オブジェクトには、必要な実際の値を含むdataフィールドと、いくつかのリクエストメタデータフィールドがあります。
selectFromResultコールバックは、元のリクエストメタデータとサーバーからのdataを含むresultオブジェクトを受け取り、抽出された値または派生した値を返す必要があります。クエリフックはここから返されるものにrefetchメソッドを追加するため、必要なフィールドを内部に持つオブジェクトをselectFromResultから常に返す方が望ましいです。
resultはReduxストアに保持されているため、それを変更することはできません。新しいオブジェクトを返す必要があります。クエリフックは、この返されたオブジェクトに対して「shallow」比較を行い、フィールドの1つが変更された場合にのみコンポーネントを再レンダリングします。このコンポーネントに必要な特定のフィールドのみを返すことで、再レンダリングを最適化できます。残りのメタデータフラグが必要ない場合は、それらを完全に省略できます。必要な場合は、元のresult値を展開して出力に含めることができます。
この場合、フィールドをpostsForUserと呼び、フックの結果からその新しいフィールドを分割代入できます。selectPostsForUser(result, userId)を毎回呼び出すことで、フィルタリングされた配列をメモ化し、フェッチされたデータまたはユーザーIDが変更された場合にのみ再計算します。
変換アプローチの比較
レスポンスを変換するために管理できる3つの異なる方法を見てきました。
- 元のレスポンスをキャッシュに保持し、コンポーネントで完全な結果を読み取り、値を派生させます。
- 元のレスポンスをキャッシュに保持し、
selectFromResultを使用して派生した結果を読み取ります。 - キャッシュに保存する前にレスポンスを変換します。
これらの各アプローチは、さまざまな状況で役立ちます。いつ使用を検討すべきかの提案を以下に示します。
transformResponse:エンドポイントのすべてのコンシューマーが、IDによる高速ルックアップを可能にするためにレスポンスを正規化するなど、特定の形式を必要とする場合。selectFromResult:エンドポイントのコンシューマーの一部のみが、フィルタリングされたリストなど、部分的なデータを必要とする場合。- コンポーネントごと/
useMemo:一部の特定のコンポーネントのみがキャッシュされたデータを変換する必要がある場合。
高度なキャッシュ更新
投稿とユーザーデータの更新が完了したので、残っているのはリアクションと通知の処理のみです。これらをRTK Queryを使用するように切り替えることで、RTK Queryのキャッシュされたデータを操作するために利用できる高度な技術を試す機会が得られ、ユーザーにより良いエクスペリエンスを提供できます。
リアクションの永続化
当初、リアクションはクライアント側でのみ追跡しており、サーバーに永続化していませんでした。新しいaddReactionミューテーションを追加し、ユーザーがリアクションボタンをクリックするたびにサーバー上の対応するPostを更新してみましょう。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
invalidatesTags: (result, error, arg) => [
{ type: 'Post', id: arg.postId }
]
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation,
useAddReactionMutation
} = apiSlice
他のミューテーションと同様に、いくつかのパラメーターを受け取り、リクエストのボディにいくつかのデータを入れてサーバーにリクエストを行います。このサンプルアプリは小さいため、リアクションの名前だけを渡して、サーバーでこの投稿のそのリアクションタイプのカウンターをインクリメントさせます。
クライアントでデータの変更を確認するには、この投稿を再フェッチする必要があることはすでにわかっているので、IDに基づいてこの特定のPostエントリを無効にすることができます。
準備が整ったので、<ReactionButtons>を更新してこのミューテーションを使用してみましょう。
import React from 'react'
import { useAddReactionMutation } from '../api/apiSlice'
const reactionEmoji = {
thumbsUp: '👍',
hooray: '🎉',
heart: '❤️',
rocket: '🚀',
eyes: '👀'
}
export const ReactionButtons = ({ post }) => {
const [addReaction] = useAddReactionMutation()
const reactionButtons = Object.entries(reactionEmoji).map(
([reactionName, emoji]) => {
return (
<button
key={reactionName}
type="button"
className="muted-button reaction-button"
onClick={() => {
addReaction({ postId: post.id, reaction: reactionName })
}}
>
{emoji} {post.reactions[reactionName]}
</button>
)
}
)
return <div>{reactionButtons}</div>
}
実際に動かしてみましょう!メインの<PostsList>に移動し、リアクションの1つをクリックして何が起こるかを確認します。

ああっと。1つの投稿が更新されたことに応答して投稿のリスト全体を再フェッチしたため、<PostsList>コンポーネント全体がグレー表示されました。モックAPIサーバーは応答前に2秒の遅延があるように設定されているため、これは意図的に目に見えるようにしていますが、応答が高速な場合でも、これは優れたユーザーエクスペリエンスではありません。
楽観的な更新の実装
リアクションの追加のような小さな更新の場合、投稿のリスト全体を再フェッチする必要はないでしょう。代わりに、サーバーで発生すると予想される内容に合わせて、クライアント上のキャッシュされたデータを更新するだけを試みることができます。また、キャッシュをすぐに更新すると、ユーザーはボタンをクリックしたときに、レスポンスが返ってくるのを待つ必要がなくなり、即座にフィードバックを得られます。クライアントの状態をすぐに更新するこのアプローチは「楽観的な更新」と呼ばれ、Webアプリでは一般的なパターンです。
RTK Queryでは、「リクエストライフサイクル」ハンドラーに基づいてクライアント側のキャッシュを変更することで、楽観的な更新を実装できます。エンドポイントは、リクエストが開始されたときに呼び出されるonQueryStarted関数を定義でき、そのハンドラーで追加のロジックを実行できます。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
async onQueryStarted({ postId, reaction }, { dispatch, queryFulfilled }) {
// `updateQueryData` requires the endpoint name and cache key arguments,
// so it knows which piece of cache state to update
const patchResult = dispatch(
apiSlice.util.updateQueryData('getPosts', undefined, draft => {
// The `draft` is Immer-wrapped and can be "mutated" like in createSlice
const post = draft.find(post => post.id === postId)
if (post) {
post.reactions[reaction]++
}
})
)
try {
await queryFulfilled
} catch {
patchResult.undo()
}
}
})
})
})
onQueryStartedハンドラーは、2つのパラメーターを受け取ります。1つ目は、リクエストが開始されたときに渡されたキャッシュキーargです。2つ目は、createAsyncThunkのthunkApi({dispatch, getState, extra, requestId})と同じフィールドの一部と、queryFulfilledと呼ばれるPromiseを含むオブジェクトです。このPromiseは、リクエストが返されると解決され、リクエストに基づいてフルフィルまたはリジェクトされます。
APIスライスオブジェクトには、キャッシュされた値を更新できるupdateQueryDataユーティリティ関数が含まれています。これには、更新するエンドポイントの名前、特定のキャッシュされたデータを識別するために使用される同じキャッシュキー値、キャッシュされたデータを更新するコールバックの3つの引数があります。updateQueryDataはImmerを使用しているため、createSliceの場合と同じ方法で、ドラフトされたキャッシュデータを「ミューテート」できます。
楽観的な更新を実装するには、getPostsキャッシュ内の特定のPostエントリを見つけ、リアクションカウンターをインクリメントするために「ミューテート」します。
updateQueryData は、行った変更のパッチ差分を含むアクションオブジェクトを生成します。そのアクションをディスパッチすると、戻り値は patchResult オブジェクトになります。patchResult.undo() を呼び出すと、パッチ差分の変更を元に戻すアクションが自動的にディスパッチされます。
デフォルトでは、リクエストは成功すると想定されます。リクエストが失敗した場合、await queryFulfilled で失敗をキャッチし、パッチ変更を元に戻して楽観的更新をリバートできます。
このケースでは、リアクションボタンをクリックしたときに投稿を再フェッチしたくないため、先ほど追加した invalidatesTags 行も削除しました。
これで、リアクションボタンを数回クリックすると、UIで数値が毎回インクリメントされるはずです。ネットワークタブを見ると、各個別のリクエストがサーバーに送信されることも確認できます。
ストリーミングキャッシュ更新
最後の機能は通知タブです。パート6でこの機能を最初に構築した際、「実際のアプリでは、何かが起こるたびにサーバーがクライアントに更新をプッシュする」と述べました。当初、この機能を「通知を更新」ボタンを追加し、HTTP GET リクエストで通知エントリをさらに取得することで偽装しました。
アプリがサーバーからデータをフェッチするための初期リクエストを作成し、時間経過とともに追加の更新を受信するためにWebSocket接続を開くことは一般的です。RTK Query は、キャッシュされたデータへの「ストリーミング更新」を実装できる onCacheEntryAdded エンドポイントライフサイクルハンドラーを提供します。この機能を使用して、より現実的な通知管理のアプローチを実装します。
src/api/server.js ファイルには、モックHTTPサーバーと同様に、モックWebSocketサーバーがすでに構成されています。初期通知リストをフェッチし、将来の更新をリッスンするためにWebSocket接続を確立する新しい getNotifications エンドポイントを作成します。モックサーバーが新しい通知をいつ送信するかを手動で指示する必要があるため、ボタンをクリックして更新を強制することで偽装を続けます。
getUsers と同様に、notificationsSlice に getNotifications エンドポイントを注入し、それが可能であることを示します。
import { forceGenerateNotifications } from '../../api/server'
import { apiSlice } from '../api/apiSlice'
export const extendedApi = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query({
query: () => '/notifications',
async onCacheEntryAdded(
arg,
{ updateCachedData, cacheDataLoaded, cacheEntryRemoved }
) {
// create a websocket connection when the cache subscription starts
const ws = new WebSocket('ws://')
try {
// wait for the initial query to resolve before proceeding
await cacheDataLoaded
// when data is received from the socket connection to the server,
// update our query result with the received message
const listener = event => {
const message = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
updateCachedData(draft => {
// Insert all received notifications from the websocket
// into the existing RTKQ cache array
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// no-op in case `cacheEntryRemoved` resolves before `cacheDataLoaded`,
// in which case `cacheDataLoaded` will throw
}
// cacheEntryRemoved will resolve when the cache subscription is no longer active
await cacheEntryRemoved
// perform cleanup steps once the `cacheEntryRemoved` promise resolves
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = extendedApi
const emptyNotifications = []
export const selectNotificationsResult =
extendedApi.endpoints.getNotifications.select()
const selectNotificationsData = createSelector(
selectNotificationsResult,
notificationsResult => notificationsResult.data ?? emptyNotifications
)
export const fetchNotificationsWebsocket = () => (dispatch, getState) => {
const allNotifications = selectNotificationsData(getState())
const [latestNotification] = allNotifications
const latestTimestamp = latestNotification?.date ?? ''
// Hardcode a call to the mock server to simulate a server push scenario over websockets
forceGenerateNotifications(latestTimestamp)
}
// omit existing slice code
onQueryStarted と同様に、onCacheEntryAdded ライフサイクルハンドラーは、最初のパラメーターとして arg キャッシュキーを、2番目のパラメーターとして thunkApi 値を持つオプションオブジェクトを受け取ります。オプションオブジェクトには、updateCachedData ユーティリティ関数と、cacheDataLoaded および cacheEntryRemoved の 2 つのライフサイクル Promise も含まれています。cacheDataLoaded は、このサブスクリプションの初期データがストアに追加されると解決されます。これは、このエンドポイント + キャッシュキーの最初のサブスクリプションが追加されたときに発生します。データのサブスクライバーが 1 つ以上アクティブである限り、キャッシュエントリはアクティブに保たれます。サブスクライバーの数が 0 になり、キャッシュの有効期間タイマーが期限切れになると、キャッシュエントリは削除され、cacheEntryRemoved が解決されます。通常、使用パターンは次のとおりです。
- すぐに
await cacheDataLoaded - WebSocketのようなサーバー側のデータサブスクリプションを作成する
- 更新を受信したら、
updateCachedDataを使用して、更新に基づいてキャッシュされた値を「変更」する - 最後に
await cacheEntryRemoved - その後、サブスクリプションをクリーンアップする
モックWebSocketサーバーファイルは、クライアントにデータをプッシュすることを模倣するために、forceGenerateNotifications メソッドを公開します。これは、最新の通知タイムスタンプを知ることに依存しているため、キャッシュ状態から最新のタイムスタンプを読み取り、モックサーバーに新しい通知を生成するように指示するサンクを追加します。
onCacheEntryAdded 内で、localhost への実際の WebSocket 接続を作成します。実際のアプリでは、これは継続的な更新を受信するために必要なあらゆる種類の外部サブスクリプションまたはポーリング接続である可能性があります。モックサーバーが更新を送信するたびに、受信したすべての通知をキャッシュにプッシュして再ソートします。
キャッシュエントリが削除されると、WebSocketサブスクリプションをクリーンアップします。このアプリでは、データからサブスクライブ解除しないため、通知キャッシュエントリが削除されることはありませんが、実際のアプリでのクリーンアップがどのように機能するかを確認することは重要です。
クライアント側の状態の追跡
最後に、1組の更新を行う必要があります。<Navbar> コンポーネントは通知のフェッチを開始する必要があり、<NotificationsList> は正しい既読/未読ステータスで通知エントリを表示する必要があります。ただし、以前は、エントリを受信したときに notificationsSlice リデューサーでクライアント側で既読/未読フィールドを追加しており、現在、通知エントリは RTK Query キャッシュに保持されています。
受信した通知をリッスンし、各通知エントリのクライアント側に追加の状態を追跡するように、notificationsSlice を書き換えることができます。
新しい通知エントリが受信される場合、2つのケースがあります。HTTP経由で初期リストをフェッチするときと、WebSocket接続を介してプッシュされた更新を受信するときです。理想的には、両方のケースに応答して同じロジックを使用したいと考えています。RTKの「マッチングユーティリティ」を使用して、複数のアクションタイプに応答して実行されるケースリデューサーを1つ作成できます。
このロジックを追加した後の notificationsSlice がどのように見えるかを見てみましょう。
import {
createAction,
createSlice,
createEntityAdapter,
createSelector,
isAnyOf
} from '@reduxjs/toolkit'
import { forceGenerateNotifications } from '../../api/server'
import { apiSlice } from '../api/apiSlice'
const notificationsReceived = createAction(
'notifications/notificationsReceived'
)
export const extendedApi = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query({
query: () => '/notifications',
async onCacheEntryAdded(
arg,
{ updateCachedData, cacheDataLoaded, cacheEntryRemoved, dispatch }
) {
// create a websocket connection when the cache subscription starts
const ws = new WebSocket('ws://')
try {
// wait for the initial query to resolve before proceeding
await cacheDataLoaded
// when data is received from the socket connection to the server,
// update our query result with the received message
const listener = event => {
const message = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
updateCachedData(draft => {
// Insert all received notifications from the websocket
// into the existing RTKQ cache array
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
// Dispatch an additional action so we can track "read" state
dispatch(notificationsReceived(message.payload))
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// no-op in case `cacheEntryRemoved` resolves before `cacheDataLoaded`,
// in which case `cacheDataLoaded` will throw
}
// cacheEntryRemoved will resolve when the cache subscription is no longer active
await cacheEntryRemoved
// perform cleanup steps once the `cacheEntryRemoved` promise resolves
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = extendedApi
// omit selectors and websocket thunk
const notificationsAdapter = createEntityAdapter()
const matchNotificationsReceived = isAnyOf(
notificationsReceived,
extendedApi.endpoints.getNotifications.matchFulfilled
)
const notificationsSlice = createSlice({
name: 'notifications',
initialState: notificationsAdapter.getInitialState(),
reducers: {
allNotificationsRead(state, action) {
Object.values(state.entities).forEach(notification => {
notification.read = true
})
}
},
extraReducers(builder) {
builder.addMatcher(matchNotificationsReceived, (state, action) => {
// Add client-side metadata for tracking new notifications
const notificationsMetadata = action.payload.map(notification => ({
id: notification.id,
read: false,
isNew: true
}))
Object.values(state.entities).forEach(notification => {
// Any notifications we've read are no longer new
notification.isNew = !notification.read
})
notificationsAdapter.upsertMany(state, notificationsMetadata)
})
}
})
export const { allNotificationsRead } = notificationsSlice.actions
export default notificationsSlice.reducer
export const {
selectAll: selectNotificationsMetadata,
selectEntities: selectMetadataEntities
} = notificationsAdapter.getSelectors(state => state.notifications)
多くのことが起こっていますが、変更を一度に1つずつ分解してみましょう。
現在、WebSocket経由で新しい通知の更新リストを受信したことを notificationsSlice リデューサーが知るための適切な方法はありません。したがって、createAction をインポートし、「いくつかの通知を受信した」ケース専用の新しいアクションタイプを定義し、キャッシュ状態を更新した後にそのアクションをディスパッチします。
「fulfilled getNotifications」アクションと「WebSocketから受信した」アクションの両方で同じ「read/newメタデータの追加」ロジックを実行したいと考えています。isAnyOf() を呼び出し、それらの各アクションクリエーターを渡すことで、新しい「マッチャー」関数を作成できます。matchNotificationsReceived マッチャー関数は、現在のアクションがそれらのいずれかのタイプに一致する場合にtrueを返します。
以前は、すべての通知の正規化されたルックアップテーブルがあり、UIはそれらを単一のソートされた配列として選択していました。このスライスを、既読/未読ステータスを記述する「メタデータ」オブジェクトを代わりに格納するように再利用します。
extraReducers 内で builder.addMatcher() API を使用して、それらの2つのアクションタイプのいずれかに一致するたびに実行されるケースリデューサーを追加できます。その内部で、IDごとに各通知に対応する新しい「read/isNew」メタデータエントリを追加し、notificationsSlice の内部に格納します。
最後に、このスライスからエクスポートしているセレクターを変更する必要があります。selectAll を selectAllNotifications としてエクスポートする代わりに、selectNotificationsMetadata としてエクスポートします。正規化された状態の値の配列をまだ返しますが、アイテム自体が変更されたため、名前を変更しています。また、ルックアップテーブルオブジェクト自体を返す selectEntities セレクターを selectMetadataEntities としてエクスポートします。これは、UIでこのデータを使用しようとするときに役立ちます。
これらの変更を行うことで、UIコンポーネントを更新して通知をフェッチして表示できます。
import React from 'react'
import { useDispatch, useSelector } from 'react-redux'
import { Link } from 'react-router-dom'
import {
fetchNotificationsWebsocket,
selectNotificationsMetadata,
useGetNotificationsQuery
} from '../features/notifications/notificationsSlice'
export const Navbar = () => {
const dispatch = useDispatch()
// Trigger initial fetch of notifications and keep the websocket open to receive updates
useGetNotificationsQuery()
const notificationsMetadata = useSelector(selectNotificationsMetadata)
const numUnreadNotifications = notificationsMetadata.filter(
n => !n.read
).length
const fetchNewNotifications = () => {
dispatch(fetchNotificationsWebsocket())
}
let unreadNotificationsBadge
if (numUnreadNotifications > 0) {
unreadNotificationsBadge = (
<span className="badge">{numUnreadNotifications}</span>
)
}
// omit rendering logic
}
<NavBar> では、useGetNotificationsQuery() で初期通知フェッチをトリガーし、state.notificationsSlice からメタデータオブジェクトを読み取るように切り替えます。「更新」ボタンをクリックすると、モックWebSocketサーバーが別の通知セットをプッシュするようになります。
<NotificationsList> も同様に、キャッシュされたデータとメタデータを読み取るように切り替えます。
import {
useGetNotificationsQuery,
allNotificationsRead,
selectMetadataEntities,
} from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
const notificationsMetadata = useSelector(selectMetadataEntities)
const users = useSelector(selectAllUsers)
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
const date = parseISO(notification.date)
const timeAgo = formatDistanceToNow(date)
const user = users.find((user) => user.id === notification.user) || {
name: 'Unknown User',
}
const metadata = notificationsMetadata[notification.id]
const notificationClassname = classnames('notification', {
new: metadata.isNew,
})
// omit rendering logic
}
キャッシュから通知リストを読み取り、notificationsSliceから新しいメタデータエントリを読み取り、以前と同じように表示し続けます。
最後のステップとして、ここで追加のクリーンアップを行うことができます。postsSlice はもう使用されていないため、完全に削除できます。
これで、アプリケーションを RTK Query を使用するように変換する作業が完了しました。すべてのデータフェッチは RTKQ を使用するように切り替えられ、楽観的な更新とストリーミング更新を追加することでユーザーエクスペリエンスを向上させました。
学習内容
これまで見てきたように、RTK Query にはキャッシュされたデータの管理方法を制御するための強力なオプションがいくつか含まれています。これらのオプションすべてがすぐに必要になるわけではありませんが、特定のアプリケーションの動作を実装するのに役立つ柔軟性と主要な機能を提供します。
最後に、アプリケーション全体が動作している様子をもう一度見てみましょう
- 特定のキャッシュタグを使用して、よりきめ細かいキャッシュの無効化を行うことができます
- キャッシュタグは
'Post'または{type: 'Post', id}のいずれかになります - エンドポイントは、結果と引数キャッシュキーに基づいてキャッシュタグを提供または無効にすることができます
- キャッシュタグは
- RTK Query の API は UI に依存せず、React の外部で使用できます
- エンドポイントオブジェクトには、リクエストの開始、結果セレクターの生成、リクエストアクションオブジェクトのマッチングを行うための関数が含まれています
- 応答は必要に応じてさまざまな方法で変換できます
- エンドポイントは、キャッシュする前にデータを変更する
transformResponseコールバックを定義できます - フックには、データの抽出/変換を行う
selectFromResultオプションを指定できます - コンポーネントは、
useMemoを使用して値全体を読み取って変換できます
- エンドポイントは、キャッシュする前にデータを変更する
- RTK Query には、ユーザーエクスペリエンスを向上させるためにキャッシュされたデータを操作するための高度なオプションがあります
onQueryStartedライフサイクルは、リクエストが返される前にキャッシュをすぐに更新することで、楽観的な更新に使用できますonCacheEntryAddedライフサイクルは、サーバープッシュ接続に基づいて時間経過とともにキャッシュを更新することで、ストリーミング更新に使用できます
次は何ですか?
おめでとうございます。Redux Essentials チュートリアルを完了しました! これで、Redux Toolkit と React-Redux が何であるか、Redux ロジックの作成と整理、React での Redux データフローと使用法、および configureStore や createSlice などの API の使用方法について、しっかり理解できたはずです。また、RTK Query が、キャッシュされたデータのフェッチと使用のプロセスをどのように簡略化できるかも理解できるはずです。
パート6の「次は何ですか?」セクションには、アプリのアイデア、チュートリアル、ドキュメントに関する追加のリソースへのリンクがあります。
RTK Queryの使用に関する詳細は、RTK Queryの使用ガイドドキュメントおよびAPIリファレンスを参照してください。
Reduxに関する質問については、DiscordのReactifluxサーバーにある#reduxチャンネルにご参加ください。
このチュートリアルをお読みいただきありがとうございます。Reduxを使ったアプリケーション開発を楽しんでいただければ幸いです!